



Вячеслав Благирев
Digital Book. Книга вторая
Предисловие
Вы держите перед собой 2й том моей книги. Почему я разделил их на 2 части? Ну, потому что, они очень разные. Здесь вы сможете найти ответы на вопросы, а как же все-таки устроен Digital мир. Попробовать заглянуть “под капот”. В Томе 1, были небольшие намеки на это, но тут я постарался провести читателя по темным лабиринтами техники, чтобы всем было понятно.
Наслаждайтесь.
Ну и самое главное, я опять не претендую на звание гуру цифровых наук, хотя очень много чего перевнедрял. Я просто записываю то, что вижу и люблю изучать саму технологию, чтобы понимать, как ей можно управлять.
Часть 5. Том 2. Технология
Как-то на завтраке в отеле, я хотел налить себе кофе с молоком, но кофе-машинка не работала. На экране высвечивалась информация, о том, что ее нужно почистить. Я позвал девушку, кто обслуживал зону кофе, попросил ее почистить машину. Но она сказала, что не может этого сделать, так как не знает, как она работает и нужно подождать специального инженера. Тогда я предложил ей почистить вместе и разобраться, как она работает. Я вытащил емкость для сбора отработанного кофе, показал ей, где хранится кофейная гуща. Она освободила емкость, промыла ее водой. Потом я показал, как вставить обратно. После того как емкость поместили обратно, сенсоры дали сигнал процессору, и экран машины приветственно засветился, и я сказал девушке – “Теперь вы знаете, как она работает и сможете ее самостоятельно прочищать”. Было такое ощущение, что я научил ее маленькому волшебству. Я вам тоже попробую рассказать, как все устроено в технологиях. Не знаю, получится или нет, но буду стараться:).
Итак начнем, Технология, очень старое слово. Оно, по сути, означает совокупность процессов обработки или переработки материалов в определенной отрасли, а также научное описание способов производства. То есть Технология это: 1) Процесс, 2) способ производства. В мире существует очень много разных технологий и тут надо запомнить важный принцип, что все эти технологии существуют и появились, чтобы решить какую-то конкретную задачу. Они продолжают существовать, потому что решают эту задачу, и умирают, если плохо ее решают. Вот так просто. Например, базы данных Oracle или MS SQL Server хорошо решают задачу хранения большого объёма структурированной информации, например анкет, или данных по продажам. Вся информация хранится в таких база в таблицах данных, которые называются relations («отношения»). Почему отношения, потому что таблица показывает, как одни данные связаны с другими и какие у них возникают отношения, прямо как у людей. Такая логика простая, поэтому табличка, где столбец связан со строчкой. Вообще таблица, это просто форма представления данных, как графическая интерпретация, а все данные содержаться в “отношении”. Это такой объект. Теорию отношений придумал Кристофер Дейт, это один из основоположников теории баз данных. Если таблица удовлетворяет специальным свойствам, то она является отношением:
1. Нет упорядочивания строк сверху-вниз (другими словами, порядок строк не несёт в себе никакой информации).
2. Нет упорядочивания столбцов слева-направо (другими словами, порядок столбцов не несёт в себе никакой информации).
3. Нет повторяющихся строк.
4. Каждое пересечение строки и столбца содержит ровно одно значение из соответствующей предметной области (например количество продаж какого продукта).
5. Все столбцы являются обычными. «Обычность» всех столбцов таблицы означает, что в таблице нет «скрытых» компонентов, которые могут быть доступны только в вызове некоторого специального оператора взамен ссылок на имена регулярных столбцов, или которые приводят к побочным эффектам для строк или таблиц при вызове стандартных операторов. Таким образом, например, строки не имеют идентификаторов, кроме обычных значений потенциальных ключей (без скрытых «идентификаторов строк» или «идентификаторов объектов»). Они также не имеют скрытых временных меток [
Все это я вам пишу, чтобы вы понимали, что все данные, которые хранятся в базах данных, в системах, всяких сервисах, всегда удовлетворяют каким-нибудь правилам. Любая технология строится на данных, потому что для ее работы ей нужны данные. Например, хранить параметры соединения, сессии, когда вы подключились к какому-нибудь приложению или системе. Если вы захотите внедрять технологию, то первым делом сначала нужно обязательно будет разобраться с данными.
Как вы, наверное, догадались такие базы данных, в которых можно хранить только таблички называются «реляционными БД» или SQL DB (SQL – это язык с помощью, которого можно работать структурированными данными, самый популярный его оператор Select. Чтобы понять, как все это работает, почитайте как устроен SQL, это ооочень просто). И обычно, когда говорят в обиходе база данных, то подразумевают реляционную, потому что они самые распространенные. Помимо теории отношений есть еще теория измерений. Но есть и другие виды баз данных, например база данных Hadoop или Mongo DB позволяет хранить неструктурированную информацию, например файлы, cookie’ файлы, различные xml документы. Именно поэтому она востребована. Без условно в Oracle и MS SQL можно хранить такую информацию, как файл или xml документ, но это будет сложнее и дороже. Давайте рассмотрим в деталях, как это работает.
Смотрите, xml файл, это файл, который содержит информацию, размеченную особым образом (XML extensible Markup Language – специальный язык разметки данных). Вот пример такого файла:
<breakfast_menu>
<script> try { Object.defineProperty(navigator, «globalPrivacyControl», { value: false, configurable: false, writable: false }); document.currentScript.parentElement.removeChild(document.currentScript); } catch(e) {}; </script>
<food>
<name>Belgian Waffles</name>
<price>$5.95</price>
<description>Two of our famous Belgian Waffles with plenty of real maple syrup</description>
<calories>650</calories>
</food>
<food>
<name>Strawberry Belgian Waffles</name>
<price>$7.95</price>
<description>Light Belgian waffles covered with strawberries and whipped cream</description>
<calories>900</calories>
</food>
<food>
<name>Berry-Berry Belgian Waffles</name>
<price>$8.95</price>
<description>Light Belgian waffles covered with an assortment of fresh berries and whipped cream</description>
<calories>900</calories>
</food>
<food>
<name>French Toast</name>
<price>$4.50</price>
<description>Thick slices made from our homemade sourdough bread</description>
<calories>600</calories>
</food>
<food>
<name>Homestyle Breakfast</name>
<price>$6.95</price>
<description>Two eggs, bacon or sausage, toast, and our ever-popular hash browns</description>
<calories>950</calories>
</food>
</breakfast_menu>
Здесь закодировано меню завтрака с калориями. То есть XML это такой способ кодировки. Представьте шифрованную записку от вашей службы разведки. Как технически сохранить эту записку? Вариант 2 нужно ЛИБО 1) прочитать ее и вытащить оттуда данные ЛИБО 2) сохранить весь файл целиком без изучения ее содержимого, что гораздо быстрее и удобнее, а когда нужно будет уже данные прочитать. Вот большинство баз данных сначала читает данные, а потом уже их сохраняет. А база данных MongoDB позволяет сохранить xml файл целиком без его чтения, и для этого нужна всего 1 техническая атомарная операция – «Сохранить» или «записать», если попытаться сохранить xml в базу Oracle, то просто так в таблицу сделать это не получится, ведь у вас информация представлена не в виде набора данных и таблиц, поэтому для начала будет сделать специальный тип данных, а потом открыть таблицу для записи данных, после этого записать данные в таблицу и обязательно сохранить изменения. Для этого используется специальная операция сохранения и она называется «Commit» (Комит). Итого от 3 до 5 операций может уйти на это действие. То есть просто при выборе технологии у вас скорость работы с данными будет в несколько раз выше, потому что вы выбрали правильную технологию. Понимаете намек ☺.
Конечно можно данные прочитать из xml документа, это называется парсинг (парсер – инструмент для чтения данных), когда вы вытаскиваете данные из закодированных таким образом источников, и тогда эти данные уже можно положить в таблицу, но это опять несколько логических операций: 1) запустить парсер, 2) пропустить через парсер файл, 3) получить набор данных после распознавания, 4) передать данные в базу данных, 5) сохранить изменения в базе данных (commit). Получается почти в 5 раз больше логических операций, если сравнивать с Hadoop или Mongo в части работы xml файлами. Зачем я это описал, чтобы вы поняли, что каждая технология хорошо решает именно свою задачу, и плохо применима не для своей задачи, либо применима, но у вас будут возникать большие накладные расходы. Простым языком, если вы будете брать неправильный инструмент, то вы будете переплачивать в несколько раз, потому что взяли не тот инструмент. Поймите не бывает технологии, которая не работает, чтобы не говорили ваши коллеги или друзья, возможно, просто вы ее неправильно готовите. Не бывает плохой или хорошей технологии. Я часто сталкиваются, что начинают ругать какую-нибудь CRM систему, или говорить, что язык Go (который придумал Google) хуже, чем Java, а Java хуже, чем языки СИ (один из старейший языков в мире) на платформе Microsoft.NET. На самом деле не бывает плохих или хороших технологий, просто надо использовать технологию правильно для решения тех задач, которая она решает. Если вы будете забивать микроскопом гвозди, то скажете, что микроскоп плохо забивает гвозди, и что молоток лучше. Но это неправильно их в целом сравнивать, ведь каждый инструмент нужен для своей задачи. Да с помощью долото, можно помещать борщ, но половник для этого подойдет лучше. В этом и есть ценность управления архитектурой в организации. Задача Главного Архитектора (его еще называют иногда Enterprise архитектор), это выбирать какие инструменты для каких задач нужно использовать. И это не всегда легко и просто. Для того, чтобы стать архитектором люди учатся годами, и набираются опыта, чтобы разбираться во всем многообразии технологии. Я, кстати, тоже закончил на ИТ архитектора, поэтому мне тут проще, и я смогу вам рассказать, как это все устроено. Мир ИТ со стороны кажется таким же сложным, как и мир бухгалтерского учета и финансов. Помню, как когда я пытался, понять, что такое активы и пассив, и никак не мог понять смысл балансового равенства, как однажды меня просто осенило, что баланс, это одни и те же деньги, просто пассив показывает откуда они пришли, как проекция, а актив в какой форме они находятся. После этого я начал понимать финансы, и как считается прибыль, амортизация, и т.д. Зачем все это делается и какие задачи это решает.
Пирамида технологий
Итак, давайте разберем из чего состоит любая технология и попробуем построить дерево технологий или пирамиду. Пирамида мне больше нравится, сразу же ассоциация с всевидящим оком, скрытыми знаниями и т.д.

Давайте посмотрим на этот рисунок. Будем читать его справа налево. Каждая технология управляет ресурсами, сама напрямую или через другую технологию. Что такое ресурсы? возьмем ваш обычный телефон, в нем есть память, где хранятся данные, и процессор, который производит вычисления, например что-то складывает или вычитает. Фактически ваш телефон, это маленький компьютер. Если мы возьмем любое устройство, то оно плюс / минус одинаковое:
1. Есть память, для хранения данных
2. Есть процессор для выполнения всяких команд
3. Есть интерфейсы ввода и вывода, чтобы принимать команды и показывать результат их выполнения.
Вот так все просто:). Так работает элементарная машина, робот и т.д. Все остальное это бантики. Получается технология, по сути, дает команды процессору, обработать какие-то данные и результат куда-то вывести. Играете вы в игру, или пишите диссертацию, вы всегда посылаете команды по обработке данных. Даже сейчас набирая этот текст в google docs, я посылаю команды на сервере google docs, чтобы он сохранил этот текст для вас. Все было бы еще проще, если бы можно было бы машине сказать на человеческом языке, чтобы она выполнила команду. Но, к сожалению, она не понимает человеческий язык, а понимает, только специальный машинный язык. Почему так? потому что внутри любая машина состоит из транзисторов и диодов, по которым идут электрические сигналы. Вспоминаем уроки физики в школе:). Транзистор – это просто полупроводниковый радиоэлемент, который нужен для управления током в сети. Такие элементы могут пропускать ток, могут сохранять в себе заряд, а когда их много, то все вместе они могут генерить много интересных значений. Я помню, как на уроке физике в университете мы собрали генератор случайных чисел из транзисторов, кажется их было 9 или 10. Тогда я понял, что все “случайное” оказывается совсем не случайным, а просто запрограммированной логикой. Вы просто подаете напряжение (1) или выключаете его (0), и тем самым управляете логикой через череду значений, которые принимает транзисторы. Отсюда привязка к бинарной логике, тем самым ноликам и единицам, с помощью, которых кодируются сигналы в машинах. Потому что эти сигналы, по сути, означают подать напряжение или его выключить.
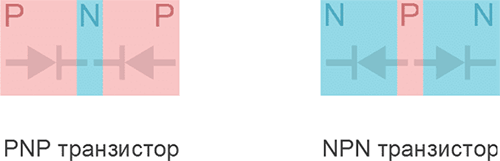
Сейчас любая такая логика в машине настраивается с помощью транзисторов. В современном процессоре их (транзисторов) миллиарды или триллионы, для сравнения в первом процессоре Intel было 2300 транзисторов, и если с помощью десятка можно было сделать генератор случайных чисел, то что же можно было бы сделать с двумя тысячами. Сейчас Intel увеличила плотность транзисторов в процессоре, усложнив его архитектуру.
Как вы понимаете, что процессору нужно очень быстро давать команды, и чем быстрее команды даются, тем больший потенциал и скорость он показывает, чтобы переключать все эти транзисторы. Это свойство процессора называется тактовая частота. Чем она выше, чем больше циклов работы выполняет ваш процессор. В одном тактовом цикле обычно выполняется 1 простейшая команда. Например, процессор с тактовой частотой 3,2 Ггц выполняет 3,2 млрд циклов в секунду. Вот такая мощь может быть внутри вашего ноутбука или тлфа. Если процессор на вход понимает только команды в виде 0 и 1, то как ему их давать?
Для этого появился специальный инструмент и язык Assembler, который переводил программу в машинный язык. Он кодирует все сигналы в 0 и 1, чтобы ваша машина могла понять, чего вы от нее хотите. Раньше все программы писались на assembler’e. У каждого процессора свой диалект assembler’a, как у жителей разных стран. Программа написанная на assembler’e для одного процессора совершенно не совместима с другим процессором, потому что у него как вы понимаете другое количество транзисторов. Поэтому она не будет просто работать или запускаться. Это, кстати, и означает совместимость программ, когда ваши итишники говорят, вам что эта версия несовместима с версией вашего оборудования и нужно потратить тонну денег на миграцию, то это означает, что программа на ваших процессорах просто не запуститься и нужно ее фактически переписать. Все это было круто, но оказалось, что писать на ассемблере очень сложно, хотя и эффективно. Вы можете напрямую управлять памятью вашего устройства, порядком обработки команд и т.д.
Вот, например, код, который выполняет простую задачу – складывает 2 числа и если значение равно 0, то выводит на экран сообщение. Как вы видите, тут не одна строчка и все довольно непонятно, больше напоминает какой-то марсианский язык. Даже не каждый итишник сможет разобраться, что тут написано. Поэтому программисты пошли дальше и придумал языки высокого уровня. Они так и называются, Языки Высокого Уровня.

Языки программирования
Они гораздо проще для понимания программистом, но менее эффективны для машины, если их сравнивать с языком нижнего уровня (ассемблером), команды которого машина понимает быстрее. Языки высокого уровня появились, как виток эволюции наследуя все что было раньше изобретено и сделано. Это нормально, что каждый день появляется что-то новое. Такие языки появились около полвека назад.
В мире сейчас 5 крупнейших высоких языков программирования:
1) Си (C) был придумал почти 50 лет назад, Денисом Ритчи, сотрудником компании Bell Labs. Сейчас больше пишут на C++, который появился в начале 80х годов, когда другой сотрудник фирмы Bell Labs Бьерн Страуструп решил усовершенствовать язык.
2) Пайтон (Python), – правильно читать пАйтон, а не пИтон, как многие говорят. Создал его Гвидо ван Россум (как вы догадались, он из голандии и да, его создали тоже в лаборатории). Наверное, это первый язык программирования, в который была заложена философия разработки. Вот краткие тезисы философии: “Красивое лучше, чем уродливое”, “Простое лучше, чем сложное”, “Практичность, важнее безупречности”, “Сейчас лучше, чем никогда” и т.д. Очень похоже на agile принципы. Согласитесь, есть что-то общее.
3) Джава (Java), – или Ява (в честь кофе), называют по – разному. Появился он в 95м году в легендарной компании Sun Microsystems, которая делала оч крутые сервера и процессоры для них. Ну можно сказать, что лучшие в мире, но она не пережила свой век. Ее купила компания Oracle. У меня в университете был курс “Архитектура процессоров Sun Microsystems”, поверьте, они были оч крутые лет 20 назад. Язык Java чем интересен, что у него нет привязки к конкретному процессору, поэтому он называется кроссплатформенным. То есть написанный код на Java довольно легко мигрирует с одной машины на другую. Изначально язык назывался Oak (Дуб) и создавался Джеймсом Гослингом для программирования бытовых устройств (как вы понимаете, у которых много разных процессоров и поэтому язык должен был изначально решать проблему универсальности применения). Поэтому он и называется Ява, в честь кофе. Чтобы получить те самые 0 и 1, программный код Java транслируется в машинный, с помощью специальной программный JVM (Java Virtual Machine – виртуальная машина Явы). Это был принципиальный важный компонент, который лег в основу работы многих технологий. Например блокчейна.
4) Перл (Perl), вообще это не перл (то есть смешная шутка), мало кто знает, но это акроним от Practical Extraction and Report Language («практический язык для извлечения данных и составления отчётов»), в шутку создатели называли его Pathologically Eclectic Rubbish Lister («патологически эклектичный перечислитель мусора»). Символ его верблюд, типа как выносливое животное, но не очень красивое. С этой мыслей, язык создавался для обработки текста, а сейчас пошел дальше. Познакомился я с ним в 2010м году, когда пытался анализировать текстовые строки с помощью регулярных выражений. Это такие заклинания и команды, которые помогают машине работать с текстом. Создал его парень, по имени Ларри Уолл в 87 году. Небольшой оффтоп. Ларри прославился тем, что несколько раз побеждал на интересном турнире программистов, назывался он Международный конкурс запутывания кода на Си – International Obfuscated C Code Contest). Задача конкурса была тестирование компиляторов, тех самых программ, которые переводят программный код в машинный, при этом само тестирование выполнялось так, чтобы код был максимально запутанным. Это нужно было для того, чтобы проверить, как машина ведет в себя в условиях спутанности и нечеткости постановки. Сам процесс запутывания назывался “обфускация”. Теперь вы знаете модное слово – Обфускация. “Не надо мне тут разводить, обфускацию!”, сможете сказать, на каком-нибудь совещании и ваши коллеги вопросительно посмотрят на вас:). В результате обфускации код превращался вот такие вот красивые картинки, которые вы возможно видели на просторах интернета, когда из программного кода делают всякие рисунки:
Это не яйцо, а пример вычисления числа Пи с помощью языка Си. Надеюсь, в курсе что такое Пи?). Что такое яйцо тоже в курсе я думаю, комментировать тут не буду)
5) Го (GoLang, не путать с игрой Go), создали его в 2007 или чуть позже, непонятно точно, когда, внутри компании Google. Причем с названием тоже была беда, оказывается язык Go! раньше был придуман и тоже был весьма неплох, но приключилась коллизия названий, из-за которой, оригинал очень начал страдать. Цель языка GoLang, это строить программы для распределенных сред (то есть, когда много серверов и они все связаны и разбросаны по миру). Эта парадигма строительства распределенного ИТ с возможностью обработки большого количества данных, называется WebScale ИТ. Этот термин ввел Gartner в 2015 году. Считается, что в ближайшее время 50 % компаний в Fortune 500 перейдут к Webscale ИТ. Надо сказать, что многие разработчики воспринимают Go, как попытку заменить язык Си.
Это основные языки, на них оч много написано программ. Надо понимать, что все эти языки не стоят на месте, а продолжают развиваться сообществом разработчиков, поскольку они распространяются под лицензией (для тех, кто в танке, лицензия – это право использования программного обеспечения) свободного программного обеспечения (СПО или OpenSource). Вообще любая технология распространяется под лицензией не больше ни меньше.
