



Робин Ли
Baidu. Как китайский поисковик с помощью искусственного интеллекта обыграл Google
Раздел 1. Краткая история: Рост искусственного интеллекта в интернет-облаке
Некоторые слова освещают историю. Другие – дорогу в будущее. Давайте начнем с краткого обзора истории интернета и искусственного интеллекта.
Многие уже знакомы с историей возникновения интернета в общих чертах. Он появился в 60-х годах XX века в американской военной лаборатории. И начал использоваться для передачи и обмена информацией между некоторыми университетами и научно-исследовательскими институтами. В конце 1980-х группа ученых разработала концепцию создания Всемирной Паутины и протокол TCP\IP (Internet Transmission Control Protocol). Основным преимуществом протокола было то, что он позволял унифицировать стандарты компьютерных сетевых коммуникаций. Значит, появлялась возможность сделать интернет доступным во всем мире. Перед человечеством открывалась новая информационная магистраль.
Около 20 лет назад 23-летний юноша Марк Андерсон изобрел браузер Netscape. Это стало настоящей бомбой – перед бизнесом широко распахнулись двери в интернет-мир. Это заставило компанию Microsoft поволноваться. Они всерьез задумались о том, что их бизнес понесет серьезные убытки от интернет-нашествия. Открывались широкие возможности для нововведений и уничтожения монополий. Поэтому молодые люди из компании Sun уволились с работы и посвятили себя разработке нового языка общения, который бы смог взаимодействовать с разными операционными системами. Плодом их стараний стал Java – новый язык программирования. Он значительно ускорил создание интернет-продуктов.
В 1997 году я вернулся в Гонконг. Тогда ни в Пекине, ни в Шанхае нельзя было найти ни одного интернет-кафе. Тогда же Ин Хэй Вэй открыл Национальную службу доступа к сети, Чжан Сяо Лун написал программное обеспечение для электронной почты Foxmail, было создано Национальное информационное общество. Мир всеобщей паутины начал приобретать свои первые очертания. Но в мире технологий продолжали появляться все новые идеи, а тайные коммерческие войны входили в эпоху своего расцвета.
В то время я работал в American Search Engine Pioneer Infoseek, которая находилась на первой линии фронта. Я чувствовал атмосферу интернет-бизнеса и страсть американцев к новым технологиям и понимал, что мы столкнулись с очередной технологической революцией. Но готов ли к ней Китай? В книге «Кремниевая долина» 1998 года подробно описаны инновации, создаваемые гениями Кремниевой долины, и их борьба между собой. После того, как я закончил книгу в 1999 году, я вернулся в Пекин в отель, построенный компанией Baidu.
Напомню, что в ту увлекательную эпоху существовало три «сверхдержавы» в Интернете – Netscape, Sun, Microsoft. Все гадали – кто же выйдет победителем из этой битвы. Microsoft казался непобедимым. Он мог усвоить любые технологические новинки. Путь Netscape сопровождали взлеты и падения. В конечном итоге она была выкуплена американским беспроводным гигантом – провайдером Verizon. Позже в руки Verizon попала и компания Yahoo. Sun в 2001 году имела 50 000 сотрудников по всему миру. А ее рыночная стоимость превышала 200 млрд долл. США. Однако, когда лопнул мыльный интернет-пузырь, компания солнца мгновенно спикировала на самое дно. Через год, в 2009 году, ее выкупила корпорация Oracle.
На этом фоне ожидался быстрый подъем новых компаний – Apple и Google с мобильной операционной системой, как ответный удар по Microsoft.
Марк Андерсон – создатель браузера Netscape, которого я описал в начале «Кремниевой долины», был практически позабыт после пика популярности в 90-х. Но он не ушел со сцены. А стал отцом ветряной промышленности Кремниевой Долины.
Интернет-технологии продолжали набирать обороты. Раньше люди боролись за интернет. А сегодня с волнением начали замечать, что он все больше выходит за рамки ПК на мобильные устройства. Это совпало с незаметным подъемом «призрака». «Призрак» – это искусственный интеллект. А интернет – всего лишь одно из его тел.
Рассвет искусственного интеллекта
История развития искусственного интеллекта предшествует интернету и сопровождается историей компьютеров. В 1956 году на конференции в Дартмуте на повестку дня был официально вынесен вопрос об искусственном интеллекте. В то время компьютер был размером с большой дом и обладал низкой вычислительной мощностью. Как вообще ученые осмелились вынести вопрос об ИИ на всеобщее обозрение?
Именно тогда Шеннон сформулировал три основных теоремы коммуникации. И тем самым заложил основу для компьютерных информационных технологий. Минский создал первый нейросетевой компьютер (он и его коллега моделировали сеть из 40 нейронов с 3000 вакуумными трубками и автоматическим индикатором на бомбардировщике B-24). А после этого написал статью на тему «Нейронные сети и модель мозга». Тогда она не произвела особого эффекта. Но позднее легла в основу концепции ИИ. Тьюринг в 1950 году представил уже известные читателю теории тестирования, а также различные концепции машинного и интенсивного обучения, генетического алгоритма.
Спустя два года после смерти Тьюринга на конференции в Дартмуте Маккарти официально представил концепцию искусственного интеллекта. Десять молодых ученых, принимавших участие в конференции, стали мировыми лидерами в области искусственного интеллекта. Но расцвет ИИ был недолгим. Все достижения ученых были похоронены результатами технологического развития.
Цель уже маячила впереди, но инфраструктура находилась в зачаточном состоянии. Искусственный интеллект сталкивался с двумя непреодолимыми барьерами. Первый – это логика алгоритмов или недостаточное развитие математических методов. Второй – недостаток аппаратных вычислительных мощностей. Например, типичная проблема – машинный перевод. Ученые день и ночь суммируют все известные правила грамматики, разрабатывают модели компьютерного языка, но машина все равно не может повысить точность перевода и выйти на удовлетворительный уровень.
Новые технологии и производственные цепочки не стали достоянием общественности. Не были изобретены захватывающие программные продукты. А государственные и бизнес-инвестиции были значительно сокращены. С середины 1970-х и до 1990-х гг. наблюдалось две волны всплеска интереса по отношению к разработкам и исследованиям, связанным с искусственным интеллектом. Но широкая аудитория оставалась в неведении. Внимание было сконцентрировано на развитии компьютера – фантастического интеллектуального инструмента.
Обыватели знакомились с искусственным интеллектом сквозь призму аркадных игр. В 1980-х в Китае на улицах появились первые игровые автоматы. Аркадные NPC (персонажи, которые не контролируются игроком) воспринимались как продукт ИИ, но легко проходились опытными игроками. Так сформировалось ошибочное представление: искусственный интеллект – то, что установлено на компьютере. Эта точка зрения никак не менялась до появления интернета и облачных вычислений.
Как закалялась сталь
В 2012 году я заметил, что в академических и прикладных областях науки произошли заметные прорывы в глубоком обучении. Например, использование метода глубокого обучения сделало возможным усовершенствование методов распознавания изображений. Я сразу понял, что мы стоим на пороге новой эры глобального поиска. Если до этого мы использовали только лишь текстовый поиск, то теперь возможными стали голосовой запрос и запрос по изображению. Например, если необходимо узнать, что за растение я вижу перед собой, то я фотографирую его и загружаю в поисковик. В течение нескольких секунд получаю его название – Flu Tong. С помощью текста сделать это было практически невозможно. Но усовершенствовался не только процесс поиска. Теперь стали возможны многие вещи, казавшиеся раньше нереальными. Распознавание речи, изображений, способность воссоздавать портрет пользователя – одни из базовых способностей человека. Как только компьютеры научатся делать то же самое, начнется новая технологическая революция. Стенографистов и переводчиков заменят машины и будут выполнять их работу лучше. В прошлое уйдут шоферы – автомобиль сможет ездить сам в разы безопаснее. В бизнесе появится умный помощник по работе с клиентами, который сможет удовлетворить все потребности и ответить на все вопросы. Искусственный интеллект даст людям новые возможности. Промышленная революция освободила людей от физической нагрузки. Теперь машины перемещают тяжести вместо нас и делают это в больших масштабах, чем было под силу человеку. Интеллектуальная революция будет решать другие вопросы. Следующие 20-50 лет мы будем свидетелями изменений и неожиданных сюрпризов. И это естественно.
Но интеллектуальная революция была бы невозможна без преданных своему делу первопроходцев. Стоит отдать им дань уважения.
После длительного периода застоя немногие ученые сохранили веру в идею искусственного интеллекта. Сейчас у Baidu есть большая и сильная исследовательская команда. Многие из ученых с 1990-х занимаются исследованиями в области машинного обучения или работают в крупных технологических компаниях. Сегодняшние достижения в области исследований ИИ – результат альтернативных подходов к работе над этой темой.
В 1990-х гг. немногие ученые, такие как Джеффри Хинтон и Майкл Джордан, настаивали на изучении машинного обучения. Ву Энда, бывший главный ученый Baidu, учился у Джордана в 90-е, а после преподавал теорию машинного обучения и даже организовал собственные онлайн-курсы. В настоящее время деканом научно-исследовательского института Baidu является Линь Юаньцин. Сю Вэй, один из выдающихся ученых корпорации, стал первым, кто предложил использовать нейронные сети для языковых моделей. Специалист по искусственному интеллекту, член американской инженерной академии, Владимир Вапник изобрел систему SVM (Support Vector Machine). Ян Лекун – лидер в области глубоких исследований, руководитель лаборатории искусственного интеллекта Facebook, изобрел специальную архитектуру сверточных нейронных сетей. А бывший директор лаборатории глубинного обучения Леон Батту является разработчиком ядра алгоритма глубинного градиента.
Исследования искусственного интеллекта прошли через несколько фаз. Первоначальные исследования ИИ основывались на правилах. Люди суммировали правила, введенные в компьютер, а сам компьютер этого сделать не мог. Следующий, более продвинутый подход основан на технологии машинного обучения. Он позволяет найти наиболее подходящие модели из больших объемов данных.
За два года развития искусственный интеллект смог поразить мир технологий. Он стал сублимированной версией технологии машинного обучения, основанной на многослойном нейросетевом компьютерном чипе. Благодаря многослойным микросхемам, которые имитируют соединение нейронов в человеческом мозге, в сочетании с усовершенствованным алгоритмом поощрения и наказания и возможностью переработки большого объема данных компьютер научился находить закономерности и вычленять модели из огромного количества информации. Это открыло новую эру в развитии интеллекта машин.
Немногие продолжали настаивать на разработке теории искусственного интеллекта, чтобы спасти уже проделанную работу. В Китае Baidu была одной из первых компаний по разработке ИИ. И, кажется, мы сделали то, о чем другие не могли даже мечтать. Шесть или семь лет назад я и Лу Цзи обсуждали прогресс, достигнутый в глубоком обучении. Мы сошлись во мнении, что готовы войти в эту сферу. В конце концов, в 2013 году я официально объявил о создании IDL (институт глубокого обучения). Он должен был стать первым институтом глубокого обучения в бизнес-сообществе. Я стал деканом не потому, что знаю больше, чем кто-либо другой. Для меня это своеобразный способ подчеркнуть степень своего внимания к предмету. А еще возможность отблагодарить тех ученых, которые не отступили в тяжелые годы.
Baidu никогда раньше не создавал научно-исследовательские институты. Наши инженеры были исследователями, а их работа всегда была тесно переплетена с практическим применением. Но я считаю, что глубокое обучение в будущем окажет огромное влияние на многие отрасли науки и жизни и шагнет далеко за пределы компетенции нашей компании. Поэтому необходимо создать специальное пространство для привлечения талантов, где бы они смогли свободно экспериментировать с инновациями, проводить исследования в неизвестных раньше областях и прокладывать путь искусственному интеллекту в жизнь человека.
На смену интеллекту
Если назвать этап просветления искусственного интеллекта версией 1.0, то машинный перевод будет следующим – 2.0. Раньше методы машинного перевода основывались на наборе слов и правил. Люди постоянно суммировали грамматические правила, но это не помогло усовершенствовать перевод. С человеческим языком машины не справляются. Особенно, когда речь идет о переводе в контексте. Например, фраза «how old are you».
Позднее появился SMT (статистический машинный перевод). Его основная идея заключается в том, чтобы посредством статистического анализа выявить общие правила использования слова или словосочетания и попытаться избежать появления нелогичных фраз. SMT имеет основные функции машинного обучения – обучение и декодирование. Этап обучения позволяет компьютеру построить модель перевода с помощью статистических данных, а затем использовать ее для перевода. Этап декодирования использует расчетные параметры, чтобы получить наиболее подходящий результат от перевода.
Исследование SMT продолжается уже более 20 лет. Для фраз и коротких предложений уже достигнут значительный прогресс. Но перевод длинных предложений, особенно со сложных языков, вроде китайского или английского, все еще оставляет желать лучшего. До недавнего времени никто не задумывался о подходе NMT (переводе, основанном на нейронных сетях). В его основе – нейронная сеть с бесчисленным количеством узлов. Исходное предложение векторизуется и передается через средний слой сети компьютеру в виде выражения, понятного для него. Затем проходит сквозь многослойную операцию и переводится на другой язык.
При таком переводе объем данных должен быть огромным, иначе система окажется бесполезной. Поисковые системы, вроде Baidu или Google, могут собирать перевод из огромного количества человеческих высказываний в интернете. Только такие объемы данных способны прокормить NMT. Система сможет самостоятельно отладить механизм перевода. И результат будет лучше, чем при SMT. Особенно, если будет достаточно информации на языке перевода.
SMT использует локальную информацию. Фраза расчленяется на сегменты. Сегменты обрабатываются и переводятся. И только потом сшиваются вместе. NMT использует общую информацию. Система кодирует фразу полностью (как люди во время перевода сначала читают предложение целиком). А потом на основе закодированной информации генерирует перевод. За счет этого достигается более высокий уровень читаемости текста.
Например, один из важных аспектов в переводе – порядок слов. Китайцы размещают определения перед определяемым словом. А в английском определение находится после. Машины часто путают этот порядок. Преимущество NMT в его способности к обучению порядку слов в языке. Это обеспечивает плавность перевода в длинных предложениях.
Традиционные методы перевода не бесполезны. Каждый из них выполняет свою функцию. Например, при переводе идиом нельзя использовать дословный перевод. Они всегда имеют устойчивое значение. Потребности пользователей интернета разнообразны: перевод разговорного языка, резюме, новостей и прочего. Поэтому одним методом сложно удовлетворить все запросы. Baidu сочетает в себе сразу несколько традиционных методов перевода: перевод, основанный на грамматических правилах, на примерах, на статистике и на нейронных сетях.
В такой модели машинного перевода человек не ищет грамматические правила, а устанавливает математические модели и параметры, чтобы помочь компьютерной сети выявить правила самостоятельно. Когда человек вводит предложение и получает на выходе его перевод, он не думает, что происходит в середине цепочки. Это называется сквозным переводом. Этот удивительный подход называется байесовским, или скрытой марковской моделью. Для решения проблемы здесь используется теория вероятностей.
С помощью байесовского метода распределения информации можно построить модель личности по вероятностным характеристикам. Например, модель мужчины предполагает, что при чтении новостей он остановится на чтении статей, посвященных войне с вероятностью в 40 %. Женская модель – только 4 %. После того как читатель выберет военные новости, в соответствии с формулой Байеса (рис. 1-2), можно более точно рассчитать его пол и другие характеристики, используя другие поведенческие данные и комплексные расчеты. Это «волшебство» математики. Но, конечно, компьютерные нейронные сети используют не только математические методы.
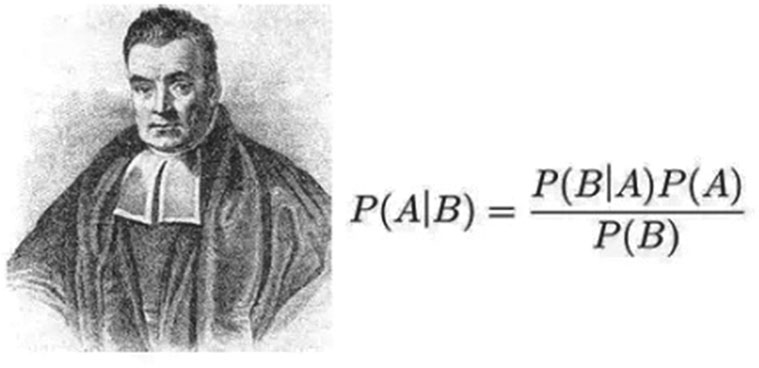
Рис. 1-1. Байес и байесовская формула[2]
Метод использования искусственного интеллекта, подобный машинному переводу, предполагает использования огромных объемов информации. Интернет сейчас способен такие объемы предоставить. Раньше ученые только мечтали о них.
Интернет был создан для того, чтобы облегчить обмен информацией. В результате произошел информационный взрыв, который способствовал ускорению развития искусственного интеллекта.
В качестве доказательства приведу игру в шахматы. В 1952 году сир Сэмюэл написал программу для игры в шашки, чтобы повысить уровень собственного мастерства. Правила игры были относительно просты. И в этом отношении у компьютера было внушительное преимущество перед человеком. Но правила шахмат гораздо сложнее. Когда президент Baidu Чжан Яцин был директором института Microsoft, он пригласил на работу талантливого компьютерщика Сюй Фэн Сюна родом из Тайваня. Этот специалист во времена IBM (International Business Machines Corporation) разработал известного робота под названием «Шахматы втемную». В 1990-х гг. искусственный интеллект не представлял собой разновидность «Шахмат втемную». Его «мудрость» была заключена в суперкомпьютере (с использованием нескольких процессоров и параллельных вычислительных технологий), благодаря которому ИИ побеждал людей-шахматистов, а в 1997 году выиграл партию у Каспарова, чемпиона мира по шахматам. Вскоре после известной игры IBM отправила технологию «Шахматы втемную» в отставку. Чжан Яцин сказал Сюй Фэн Сюну: «Изобрети технологию для игры в Го, а потом найди меня и выиграй». Пока Чжан Яцин не покинул Microsoft, Сюй Фэн Сюн его так и не искал.
Технология «Шахматы втемную» сталкивается с некоторыми трудностями, которые на сегодняшний день не могут быть преодолены. Достичь прорыва в этом направлении так же сложно, как покорить Вселенную. Модель, которая опирается на алгоритм дерева решений, исчерпывает свои возможности и выходит за пределы пропускной способности компьютера. Алгоритм постоянно совершенствуется, но проблему в вычислениях решить пока не удается. У искусственного интеллекта есть все предпосылки для того, чтобы быть устойчивым перед лицом восточной мудрости. И новая эра уже не за горами.
Интернет-конференция
Технология «Шахматы втемную» представляла собой модель искусственного интеллекта, но, кажется, не имела ничего общего с интернетом. Но развитие облачных вычислений и возможности управления большими объемами информации наконец-то объединили ИИ и интернет в одну устойчивую технологию, которая существенно отличается от «Шахмат втемную». Распределенные вычисления в сочетании с большими объемами информации и новым алгоритмом принятия решений демонстрируют успешное сочетание человеческого и машинного интеллекта.
В 2016-2017 годах AlphaGo (программа для игры в го) всколыхнула человечество. Процесс ведения игры AlphaGo отличается и от человеческого мышления, и от «Шахмат втемную». Проще говоря, механизм питается десятками миллионов человеческих шахматных партий. Выражаясь более профессионально, успеху AlphaGo способствовали алгоритм поиска Монте-Карло и механизм распознавания образов, основанные на глубоком обучении. Однако ни его предшественники, ни «Шахматы втемную» к технологии глубоко обучения отношения не имели.
Согласно исследованиям, AlphaGo не изобретает собственный механизм игры, а изучает десятки миллионов игроков (массивы данных). Он запоминает каждый ход, каждую игру из миллионов ситуаций и использует данные для обучения с помощью нейронной сети. Все это делается для того, чтобы иметь возможность предсказать, как мастер-человек сумеет выйти из той или иной ситуации. На практике компьютер анализирует текущую ситуацию и находит ее аналоги в прошлом. Затем ищет возможные варианты развития и выбирает несколько наиболее оптимальных. Таким образом, вместо того, чтобы пробовать все возможные варианты, он останавливается на наиболее выгодных. Тем самым сокращает объем вычислений. Система не истощается и получает защиту от поражения. Этот подход похож на человеческий. Мы не пробуем все подряд, а выбираем несколько вариантов, опираясь на опыт и чувства. Но после того, как сделаем свой выбор, мы все еще должны производить подсчеты и сравнения в поисках оптимального хода. Машина же передаст эти расчеты алгоритму поиска Монте-Карло.
Ниже я использую метафору. Она не точная, но достаточно понятная.
Поиск решения по методу Монте-Карло – это оптимизация предыдущего алгоритма дерева решений. Предыдущий алгоритм, даже если он предоставлял качественный вариант решения задачи, должен был быть единственным в каждой точке для того, чтобы выбрать следующую ветвь с бесконечным множеством менее рациональных вариантов решения.
Метод Монте-Карло основывается на тонкостях теории вероятности. Представим шахматную ситуацию, где сеть глубокого обучения дает три возможных варианта на ход – А, В, С. Три точки в качестве корневого узла можно представить, как три дерева, каждое из которых имеет бесконечное число ветвей. Метод Монте-Карло не проверяет каждую из ветвей, но отправляет три миллиона муравьев по одному на каждую ветвь, чтобы те быстро поднялись на верхушку дерева (то есть, чтобы они шли до тех пор, пока не доберутся до варианта, который обеспечит победу). Некоторые из них доберутся до победной точки. Предполагается, что все муравьи ищут наиболее эффективное решение, а не вариант, в котором партия завершится поражением.
Предположим, что из 1 миллиона муравьев, которые отправились по ветке А, только 300 тысяч дошли до победного конца. По ветке В – 500 тысяч. По ветке С – 400 тысяч. Система понимает, что вероятность победы на ветке В гораздо выше, и выбирает именно этот вариант хода. Таким образом, вероятностный метод значительно сокращает количество вычислений по сравнению с методом исчерпывания.
Почему мы отправляем именно 1 миллион муравьев для исследований, а не 100 тысяч или не 10 миллионов? Это зависит от вычислительной мощности компьютера и приблизительной оценки конкурентов. Если в данной ситуации, чтобы получить более высокий коэффициент выигрыша нам требуется только 100 тысяч муравьев, мы отправим 100 тысяч. Но чем больше муравьев отправляются на дерево в одно и то же время, тем выше требования к вычислительной мощности компьютера.
Чип процессора и графический процессор (GPU), нейронные сети и метод Монте-Карло создают возможности, которые не могут сравниться с человеческими. В результате глубокого обучения искусственный интеллект моделирует способности человека, которые аналогичны сумме способностей 10 миллионов шахматистов.
Умные читатели, даже не понимая математическую теорию, способны уловить механизм работы AlphaGo. Хотя алгоритмы и стратегии гораздо сложнее, чем описано выше. AlphaGo на своем примере демонстрирует уровень развития глубокого обучения и искусственного интеллекта. Но на самом деле, на сегодняшний день существует множество научно-исследовательских институтов и талантливых ученых, которые делают сверхъестественные вещи в данном направлении.
После того, как поведение человека начало фиксироваться в виде данных посредством интернета, у искусственного интеллекта появилось полноценная пища, чтобы идти в ногу с человечеством и помогать ему во всех сферах жизни. Машинный перевод, распознавание речи, изображений опираются на клики пользователей Интернета. Почему точность поисковой системы Baidu трудно сравнить с другими поисковыми системами? Потому что Baidu обладает самым большим объемом данных, самым продвинутым алгоритмом принятия решений и самой сильной командой. Каждый клик пользователя тренирует мозг Baidu и рассказывает о том, что человек хочет больше всего.
Когда искусственный интеллект переживал этап застоя, люди думали, что машина никогда не сможет думать так же, как человек. Но после 1990-х мы поняли, что машина и не должна думать так же, пока мы в состоянии сами решить свои проблемы. У лингвиста Хомского спросили: «Может ли машина думать?» Это был позаимствованный датским компьютерным ученым Дикстра риторический вопрос: «Будет ли подводная лодка плавать?» Ответ был такой: «Подводная лодка не плавает, как рыба или человек, но ее способности очень высоки».
Если мы оглянемся назад (не только на историю развития интернета), то поймем, что вся история развития промышленности – это шаги по направлению к развитию искусственного интеллекта. Кевин Келли отмечал, что самоприводящийся поршень парового двигателя уже представляет собой конструкцию, которая содержит элементы «эволюции». Стремление к автоматизации – эволюционная сила ИИ.
Когда началась промышленная революция, паровой двигатель появился в угольных шахтах и ямах. Эффективность двигателя пара была низкая, энергия, особенно при добыче угля, требовалась значительная, и спрос на дешевую рабочую силу сохранялся существенный. Дело в том, что при добыче угля использовалось много воды. А вода, в свою очередь, была топливом для парового двигателя. После того, как в шахтах впервые была применена новая технология, она постоянно продолжала совершенствоваться для содействия промышленной революции. С искусственным интеллектом то же самое: данные – это топливо для двигателя искусственного интеллекта, а когда ИИ получает достаточное количество данных, он может работать дальше.
Без накопления данных о деятельности человека компьютер не может стать объектом обучения. Это стало возможным благодаря развитию интернета и развитию методов сбора информации. А также благодаря исследователям ИИ, не все из которых являются учеными в сфере компьютерных технологий. Некоторые из них проводят биологические исследования, некоторые – инженерные. Некоторые изучают математику, архитектуру компьютерных чипов или автоматизированную итеративную оптимизацию компьютерных программ. Но однажды результаты изысканий сходятся в одной точке. И на этом месте рождается искусственный интеллект.